Overview
How can we teach a robot to predict what will happen next for an activity it has never seen before? We address this problem of zero-shot anticipation by presenting a hierarchical model that generalizes instructional knowledge from large-scale text-corpora and transfers the knowledge to the visual domain. Given a portion of an instructional video, our model predicts coherent and plausible actions multiple steps into the future, all in rich natural language. More details of the model can be found in our paper.
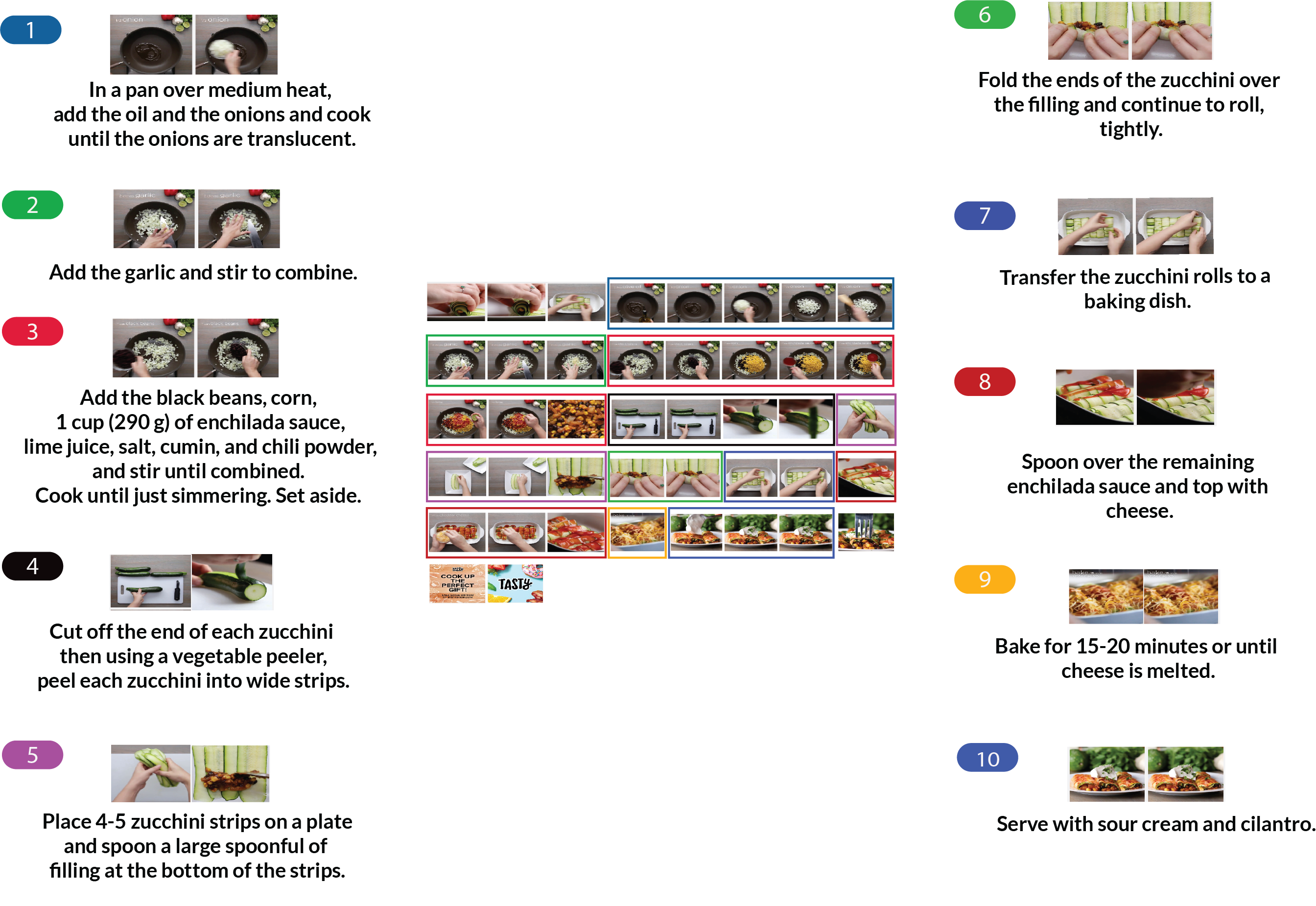
To demonstrate the anticipation capabilities of our model, we introduce the Tasty Videos dataset, a collection of 2511 recipes for zero-shot learning, recognition and anticipation. Each recipe features an ingredient list, step-wise instructions and a video demonstrating the preparation. Each recipe is annotated with the temporal boundaries for the steps within the video.